Need for data: A survey
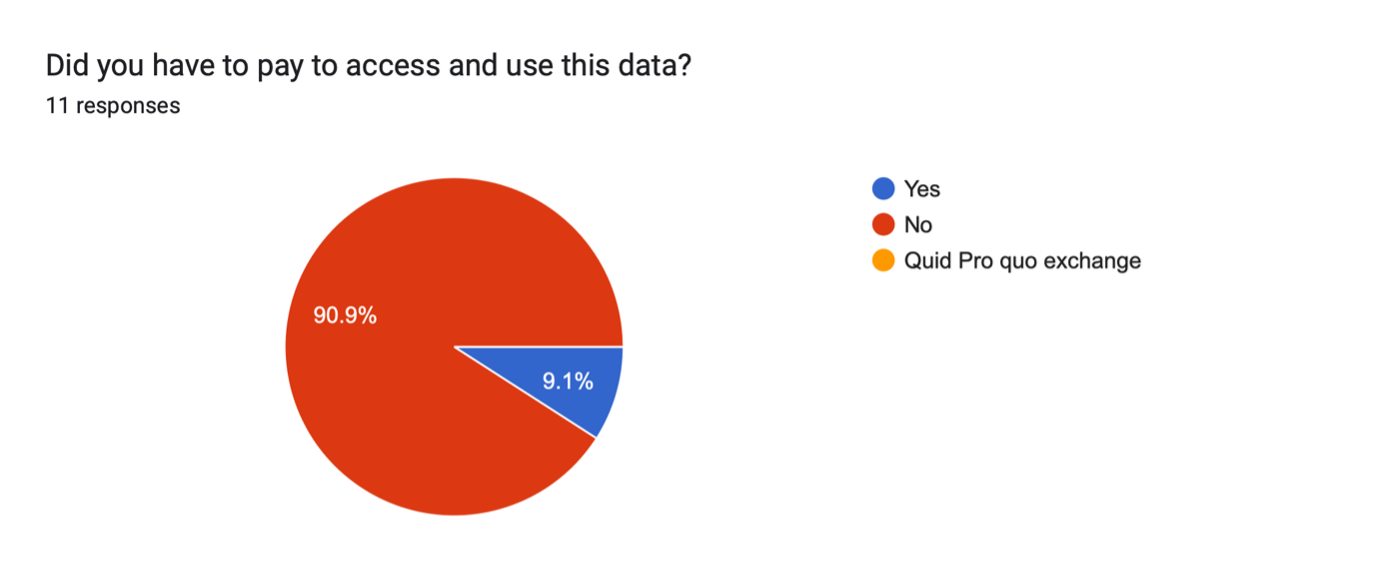
From a legal perspective, a taxonomy of data used in AI research and development shows that there is copyright data (i.e., copyright-protected materials as data), personal data, contract-based data, etc. To get a sense of the kind of data that is prevalent in AI research within Africa and also to pinpoint the prevalent data sources, I had a set of survey questions as follows: Nature/ kind of data researchers have used? Source of data; Did you have to pay to access and use this data?
|
What kind of data HAVE you used in your research? Please be as specific (e.g. English language text from journal articles; social media posts in X language; etc.) or as brief as you'd like. |
|
Online Reviews |
|
African languages text data for a variety of text-based NLP projects |
|
English and another SA official language data from government sites and documents |
|
Social media data, online dataset which are publicly available |
|
English text f4om journal articles |
|
social media posts in English |
|
English language text from journal articles, own survey data |
|
Affective recognition data |
|
English language text from journal articles |
|
SDG Research Metadata Repositories |
|
YouTube, open-source data |
|
Where did you get your data from? (e.g. Facebook; corporate website) |
|
Review Website |
|
Many times we had to curate the data ourselves. For the text-based projects, we got most of the data from news sources |
|
Government website |
|
Online and publicly available data |
|
Database |
|
|
|
University library, own research |
|
Kaggle |
|
UP Library website |
|
Partner Organisation |
|
Yotube, social media |
I then shared 5 different stories to illustrate the (various) roles that law/legal frameworks play (“pain points”?) in data science research. There was another survey after sharing the stories. This new survey sought to identify which of the stories resonated the most with the experiences of the attendees.
Story 1 (Remove infringing and/or offending content but respect the right to freedom of expression): This story was about the interaction between the legal counsel of a new social media platform and the data science team in the same company on striking the right balance between the need to remove inciting content and freedom of speech. This story highlights the need to bridge the knowledge gaps that data scientists and lawyers have with each other’s work and shows how multi-disciplinary dialogue between the two fields may result in the design of better AI systems.
Story 2 (Housing policy could benefit from Airbnb data): This story related to a study that explored the impact of Airbnb on the housing market and housing policy. The researchers grappled with the question of whether licences were needed to scrap data from the Airbnb platform. Given the uncertainties around the UK text and data mining (TDM) exception, UBDC has decided to cooperate with CREATe so that they can proceed with more legal certainty – which led to the commissioning of the paper by Dr Sheona Burro.
Story 3 (Scrap our website for your training data for free but…): Here, some South African data science researchers have shared that they found a web platform that has tons of text and audio files in African languages. The platform owner agreed to grant access to the files for free to use the data to train NLP models. However, in exchange, the platform owner wanted to solely or at least co-own the NLP model created as a result of the access.
Story 4: Some South African researchers needed public health data on the Covid-19 pandemic in a more accessible format but there were concerns from government health departments about who takes responsibility if that data was wrongly labelled.
Story 5 (Of FAIR, CC0 and release of datasets): Many data science projects result in the creation of labelled datasets which in turn necessitates thinking around the management, administration and use of such datasets. A good number of funders in Africa require data scientists to license datasets using Creative Commons (CC) licences. To comply with the FAIR data principles, AI researchers increasingly use the Creative Commons zero (CC0) licence to release their trained datasets for public use and reuse. There are debates around the extent to which this practice could lead to ‘AI data laundering’.
Stories of data science-law interaction that resonate with data scientists in Africa

Conclusion
While the number of survey responses is too small to make conclusive statements, it was interesting to see the prevalent data sources and how copyright protection may apply to some of those data (e.g., journal articles, databases). It was also impactful to see that in over 90% of the cases, researchers did not have to pay to access that data. That said, it would be interesting to understand the extent to which financial constraints dictated the kind of data that researchers use.
Regarding the experiences of researchers on the interface between data science and law, Story 1 resonated the most with respondents’ experiences. Of course, broadly construed ‘inciting or offending content’ could be copyright infringing content. South Africa’s Electronic Communications and Transactions Act refers to ‘unlawful activity’. Story 3 was the second prevalent experience and correlates with global questions on the same issue. If as some scholars have suggested, “extracting information, patterns and correlations from large sets of copyrighted works should not be subject to the authorization of right holders”, then it would not be the place of rightholders to seek (copyright) ownership of AI tools created/developed as a result of such information extraction. But there is the question of the copyright status of labelled datasets which are essentially (in the case of ‘copyright data’) annotated and tagged copyright data in machine-readable formats. These are just a few of the legal uncertainties that researchers have to grapple with.
To respond to the two surveys, which are still open, see here and here. The seminar recording is available here.
 Reviewed by Chijioke Okorie
on
Friday, August 25, 2023
Rating:
Reviewed by Chijioke Okorie
on
Friday, August 25, 2023
Rating:



 Follow the IPKat on LinkedIn
Follow the IPKat on LinkedIn 

![[GuestPost] G1/24: Tuning in! A take on the state of proceedings before oral proceedings](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjZhEivE5bp7QOwZsyZXAXbVNYSmLjUthkB2Q7fm1_dpB97u5lIQeyWT9ZadUTAH3Z-hXn13VpW4vBDRPx9emCnoDV6tbUTkyvfmqPv1nNInL8XMdrAtSZ2hcRQr2LjxKovC9wTk_XyZxQ0CtX1MUrO_Muz3OJ4ld8AftymsdUmKD7xNksYMwk6/s150/Picture%201.png)

![[Guest post] ‘Ghiblification’ and the Moral Wrongs of U.S. Copyright Law](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhxl1BQBAW3Y-asjb1xXB9eA4DYy77fky6WgR-prC-_6DeBbDqOgCUDWyiz0Q3B23MWWAXnkbS2H2js7OUwA0JQXAHmsyVFgGIHeJz7zJ791vTzOD-4SJqWFIuywFXQyd3ahybbdZd4e8IEVfcNqctvyR8lumv_Gix6Tsw5cSvbHpTI1nwvztDuAQ/s150/IMG_2179.HEIC)



![[Guest book review] The Handbook of Fashion Law (with a discount code)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgB4h2AdqJKwq9O3Ft4Mb7C39tv_NeFpkzrOfvhIsuwAkM_ops2Hgj7fdwzq_TQsjQDvQrQa-yyC9Q9pNiugseXRlUaMdsr_cmYUbh9lH8HDECMCbsTuNboVgpafyEhkgDkVS6ruHkuz8Sx0QVGI_1S8R9kbsHdNIYrRjqhyphenhyphen010_txjJUYvlZOtWA/s150/Fashion%20Law%20Book%20Bicture.jpg)




No comments:
All comments must be moderated by a member of the IPKat team before they appear on the blog. Comments will not be allowed if the contravene the IPKat policy that readers' comments should not be obscene or defamatory; they should not consist of ad hominem attacks on members of the blog team or other comment-posters and they should make a constructive contribution to the discussion of the post on which they purport to comment.
It is also the IPKat policy that comments should not be made completely anonymously, and users should use a consistent name or pseudonym (which should not itself be defamatory or obscene, or that of another real person), either in the "identity" field, or at the beginning of the comment. Current practice is to, however, allow a limited number of comments that contravene this policy, provided that the comment has a high degree of relevance and the comment chain does not become too difficult to follow.
Learn more here: http://ipkitten.blogspot.com/p/want-to-complain.html